

Demystifying Degrees of Freedom
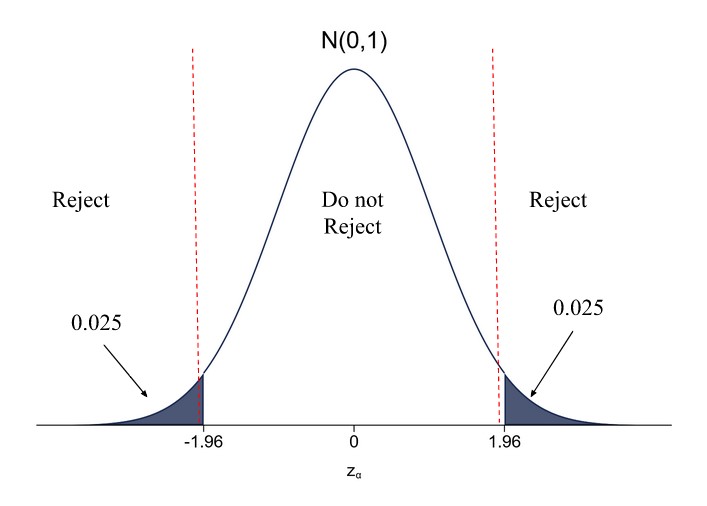
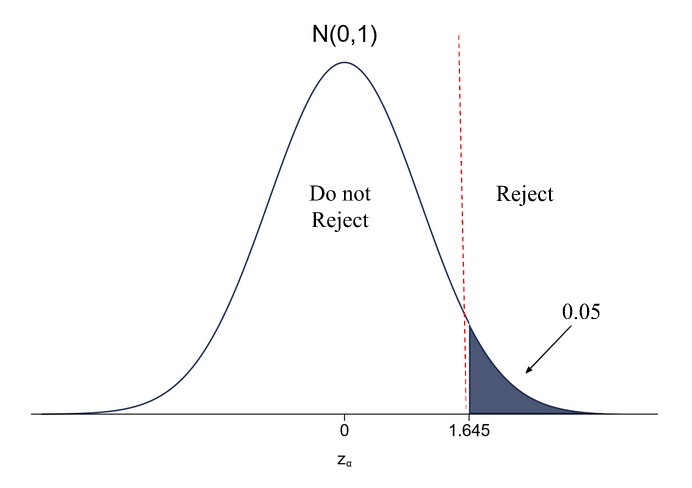
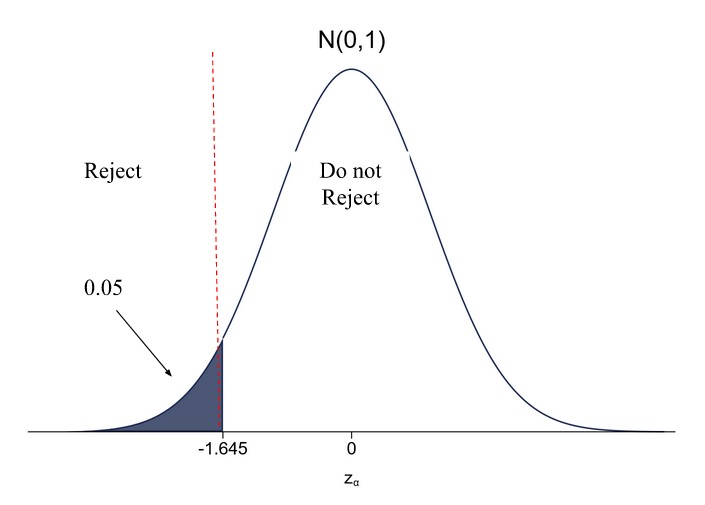
Demystifying Degrees of Freedom When doing hypothesis testing, everyone has encountered tests that depend on the so-called ‘degrees of freedom’. However, explanations of what degrees of freedom actually mean are lacking from most textbooks, and if they exist, these explanations are highly formulaic and lack intuition. Indeed, the phrase ‘degrees

Assumptions Under Which The OLS Estimators are BLUE
Assumptions Under Which The OLS Estimators are BLUE An Ordinary Least Squares (OLS) linear regression is one of the most common and widely used techniques in empirical research. In a nutshell, an OLS linear regression relates an outcome Y to a independent variable X by minimizing the sum of squared